Видео с ютуба Llm Inference

Почему делать логические выводы сложно...

AI Inference: The Secret to AI's Superpowers

Deep Dive: Optimizing LLM inference

Освоение оптимизации вывода LLM: от теории до экономически эффективного внедрения: Марк Мойу

Understanding the LLM Inference Workload - Mark Moyou, NVIDIA

Large Language Models explained briefly

What Is Llama.cpp? The LLM Inference Engine for Local AI

Faster LLMs: Accelerate Inference with Speculative Decoding

Understanding LLM Inference | NVIDIA Experts Deconstruct How AI Works
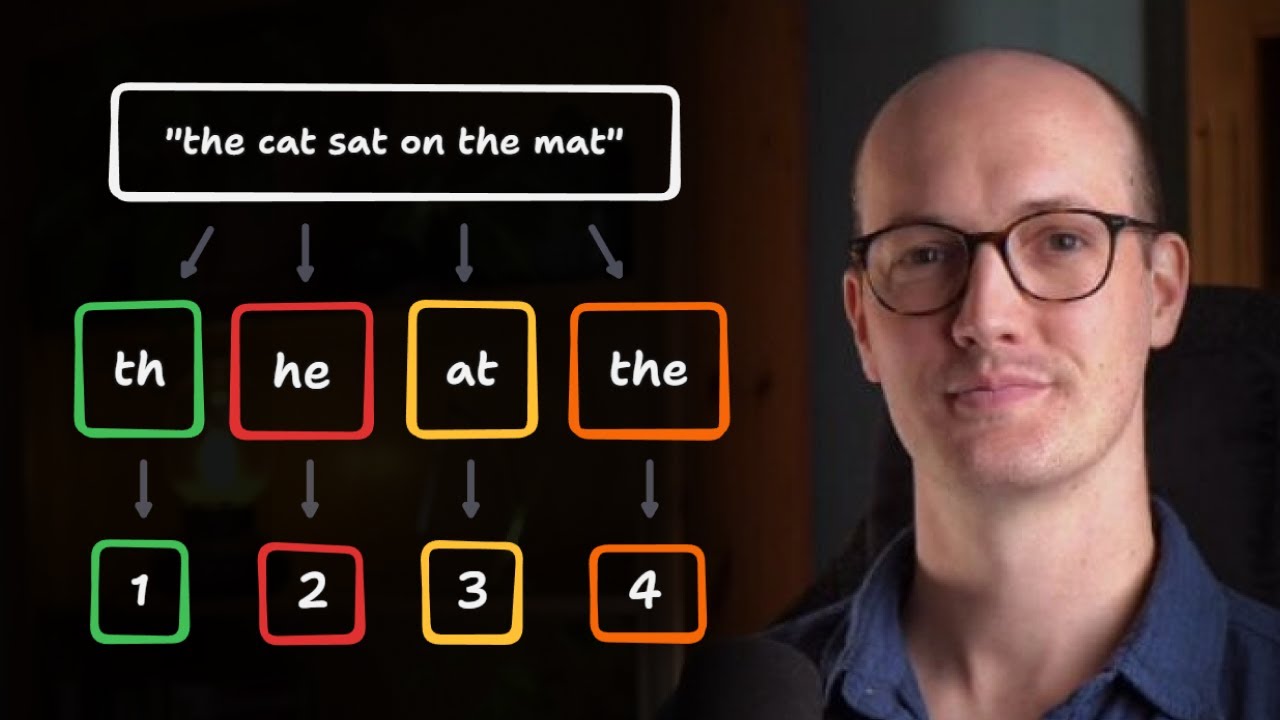
Большинство разработчиков не понимают, как работают токены LLM.

What is vLLM? Efficient AI Inference for Large Language Models

Невероятно быстрый вывод LLM с этим стеком

Deep Dive into LLMs like ChatGPT

LLM inference optimization: Architecture, KV cache and Flash attention

Stanford CS336 Language Modeling from Scratch | Spring 2025 | Lecture 10: Inference

High Performance LLM Inference in Production

Distributed inference with llm-d’s “well-lit paths”

Optimize LLM inference with vLLM
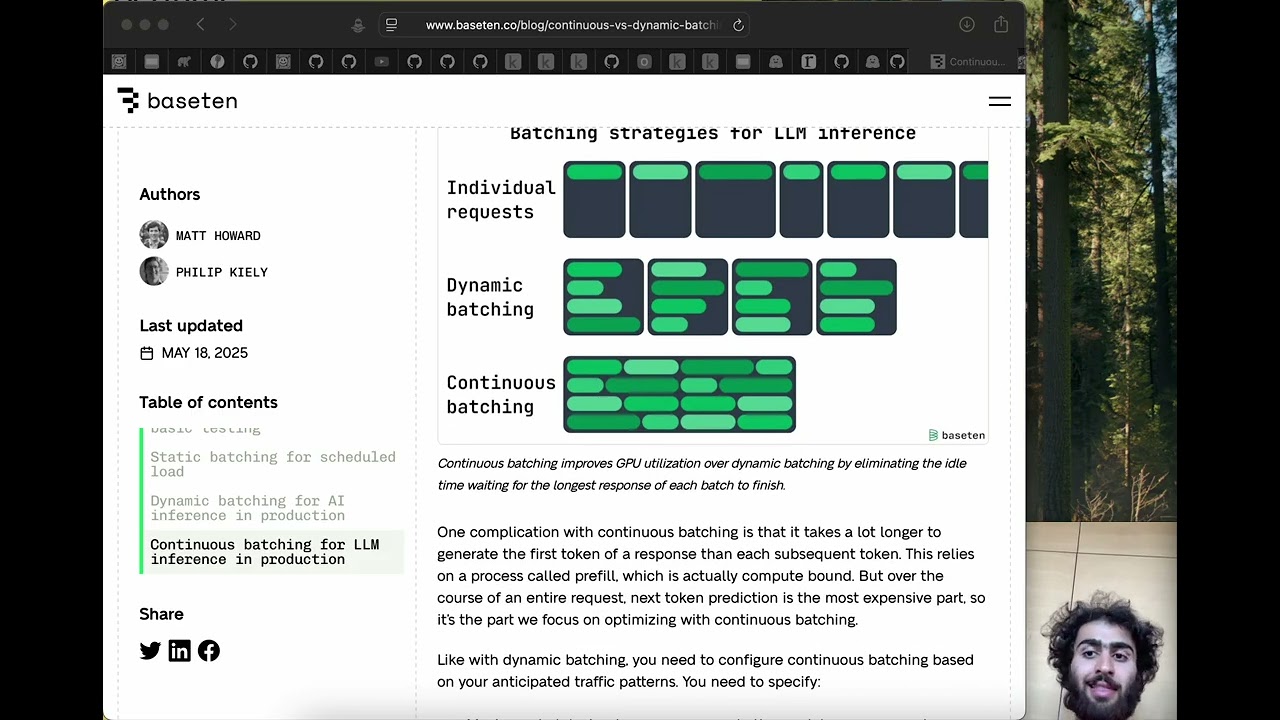
Gentle Introduction to Static, Dynamic, and Continuous Batching for LLM Inference

How the VLLM inference engine works?